Overview of AI Security and Defense
Overview
As machine learning techniques have been widely used in real-world applications, there are growing concerns regarding the security of AI security and how to defend against potential attacks. In this post, I will give an overview of security concerns in AI and machine learning domain. Potential defense strategies will also be covered.
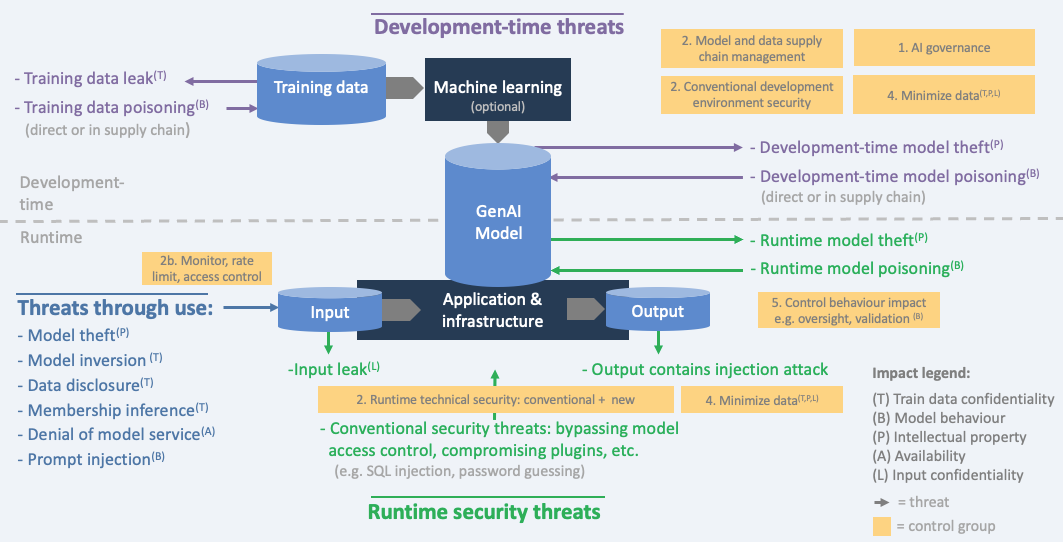
As the figure below shows, security concerns can arise in different stages in the whole AI pipeline, from model training to model deployment. These threats can lead to different consequences, such as training data leak, undesired output during inference, or even model theft during runtime.
I will mainly discuss the following security threats related to: training data confidentiality, model behavior, intellectual property, input confidentiality
Training Data Confidentiality
Training data leak can happen in many scenarios. In this blog, I will mainly discuss data leak through models. As we know, ML models including CNNs, Transformers or LLMs are trained to learn patterns in the training datasets. If we put it in another way, training data information is encoded in model weights during training. As a result, by interacting with the model, there are many ways to steal or reveal the training samples. Researchers have shown that data leak can happen in the following cases:
Model Inversion
Coming soon
Extraction Attacks
Extraction attacks happens due to the fact that a pre-trained model memorizes training data, in particular for large language models (LLMs). As the figure below shows, some prompts can trigger a model to output the extract data in the training set. The extracted data may contain private information, like personal identification information (PII), which can cause critical concerns.
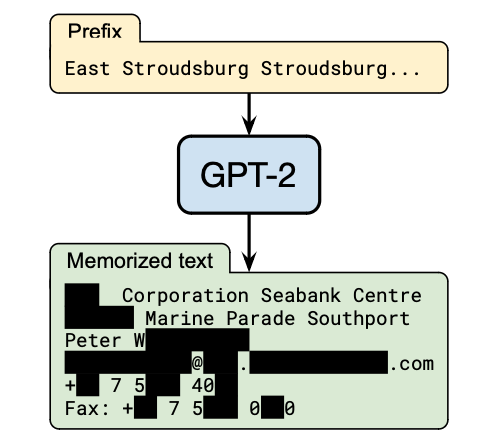
Again the reason is that the pre-trained model overfits to some training datasets. As a result, as the example above shows, a prefix prompt can immediately induce the model generating a response that is exactly the same as the training samples.
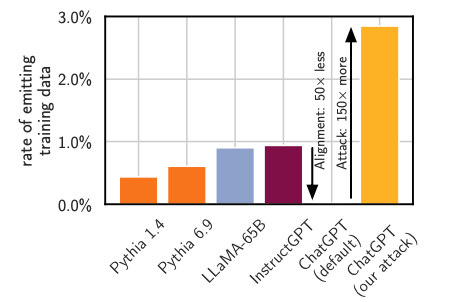
One question is: how serious this issue can be? Or specifically, how many samples
will be revealed? Researchers have shown that for even production models like ChatGPT,
there are still quite a few samples that can be extracted by trying multiple
queries, as shown in the figure below.
For model such as ChatGPT, even 3% samples can be exactly extracted [1]. Considering
the size of the pre-trained dataset of ChatGPT, the ratio is significant.
How should we prevent that? Unfortunately, there is no effective way for addressing the issue. General idea is to train the model but avoid overfitting on the training dataset. For instance, by adding small perturbation in input or hidden states, the trained models will not learn the exact inputs, thereby to some extent alleviating the problem. However, adding perturbation inevitably affect the model utility.
Model Behavior
Controlling a model’s behavior is another critical concern in current AI system. An adversary may provide specific inputs and prompts to break down the AI system, or change its behavior for their own purpose.
Backdoor/Trojan Attacks
Backdoor attacks is one of these concerns that control the model’s behavior. An adversary can create a Trojaned model that performs pretty well on normal inputs, but is fully controlled with inputs that have certain specific pattern.
As the example below show, a Trojaned model can correctly classify normal Stop signs. However, when a small yellow patch is added, the Trojaned model will classify it as speed limit. If the model is deployed in the real world, it can cause severe consequences.

The attack is very possible when an adversary deliberately add some negative samples during training. The trained model will be triggered if inputs with similar patterns are fed after the model is deployed.
One potential solution for this issue is to have a detector that detects if the
model to be deployed is trojaned. Works like [2] design a detector that learns
output distributions of the benign model and the trojaned model.
Therefore, it can detect the trojaned model when the distribution of the model’s
output is different from the benign model.
Prompt Injection Attacks
The prompt injection, in general, is an attack that uses carefully crafted prompts to make the model perform unintended actions, such as generate malicious output/code, or leak sensitive data.
The extraction attack mentioned before can also be seen as a way to craft special prompts and trigger the model to output private information in the pre-trained dataset. Other cases may arise when an adversary provides malicious prompt and cause the model to ignore previous prompts, or even leak previous prompts.
Intellectual Property
This concern arises when an adversary can find a way to get the model architecture or parameters. Imaging in current LLM era, commercial models such as ChatGPT remain private. It will raise considerable concerns if the model can be revealed or stolen.
Model Stealing Attacks on CNNs
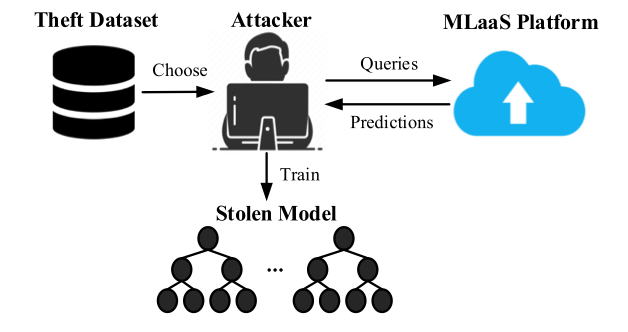
One popular way for stealing a model is investigated in convolutional neural networks (CNNs) [3].
An adversary can first query the ML service using a fake dataset, then obtain
the predictions (a.k.a. labels) from the ML service.
Then, with the fake datasets and the predicted labels, the adversary can train a
shadow model that mimics the target model’s behavior, as shown in the figure below.
While the stolen model may not be the exact target model, it can still mimic the target model’s behavior.
Model Stealing Attacks on LLMs
Interestingly, even close LLMs can be hacked and revealed part of the model architecture.
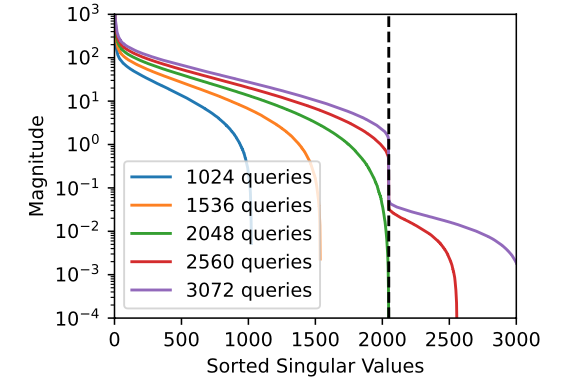
One interesting method from [4] can guess the hidden dimension
size (only the last layer before Softmax). In particular, if looking at the output layer
in most LLMs, they have the following computation
[ y = \text{Softmax}(W \cdot g(x)) ]
where $y$ in the probability vector on all possible tokens given input $x$. $g(\cdot)$ is the model that compute the hidden states.
The attack is based on the observation that given sufficient number of query inputs, if grouping all output probability vectors together as
[ { y_1, y_2, \cdots, y_n } ]
their rank will upper bounded by the dimension of $W$, which corresponds to the hidden dimension.
Therefore, with a sufficient number of queries, we can finally obtain the dimension of hidden states by analysing the rank of all output vectors. As shown in the figure below, given sufficient number of queries (e.g., 3072), we observe that there is a point where singular values changes abruptly (around 2000). Considering the typical size of hidden state vectors, the attack can guess the size of hidden states is 2048, which is a valid guess.
Input Confidentiality
[1] https://arxiv.org/abs/2311.17035
[2] https://arxiv.org/abs/1910.03137
[3] https://ieeexplore.ieee.org/abstract/document/8489592
[4] https://arxiv.org/abs/2403.06634