LLM Alignment with Model Editing
Language models (LMs) have greatly propelled the research on natural language processing. However, LMs also raise concerns regarding the generation of biased or toxic content and the potential disclosure of private information from the training dataset.
In this project, we explore a new way to align and rectify language models to remove undesired knowledge. We investigate popular language models such as GPT, Alpaca. We show that these pre-trained language models can be edited so that the models give less undesired responses.
Overview
For a pre-trained (language) model, model weights encode knowledge about the training dataset. That is, if a training dataset has biased records, this biased knowledge will be learned and encoded in weights after pre-training.
Therefore, in this project, we aim to find a way to locate which parts of the model may encode the undesired knowledge. If we can locate them, then we can remove them from the pre-trained model.
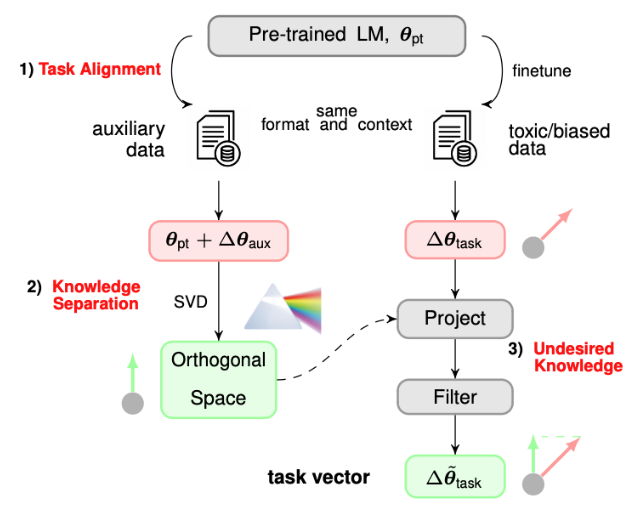
Analyze Weights in Orthogonal Space
Demystifying contribution of weights is non-trivial. Weights in pre-trained models are usually correlated, it is difficult to separate them and analyze their individual contribution to models’ behavior. To address this challenge, we first convert weights of a pre-trained model in orthogonal space as
[ W = \sum_{k=1} W_k = \sum_{k=1} s_k \cdot \boldsymbol{u_k} \cdot \boldsymbol{v_k^*} ]
where $s_k, \boldsymbol{u_k}, \boldsymbol{v_k}$ denotes singular values and principal vectors obtained from singular value decomposition (SVD).
The reason for converting weights into orthogonal space is that we can effectively decompose weights and analyze contribution of each component. In particular, given two orthogonal weight matrices $W_1, W_2$, we can easily see that their output given the same input $\boldsymbol{x}$ are also orthogonal:
[ \boldsymbol{y}_1 = W_1 \cdot \boldsymbol{x}, \boldsymbol{y}_2 = W_2 \cdot \boldsymbol{x} ]
Locate The Components with Undesired Knowledge
With the obtained orthogonal components from a pre-trained model, we can find a way to decide if a certain orthogonal component encode undesired knowledge. Like what we show in the figure above, we can fine-tune the pretrained model on a downstream dataset with known undesired knowledge (e.g., records with gender bias). Then we compared the fine-tuned model weights with the pre-trained model weights, and check which orthogonal components observe large changes.
If mapping the fine-tuned weights to the pre-trained orthogonal space, and an orthogonal components observe significant changes, then the orthogonal component can possibly encode undesired knowledge in the downstream dataset.
Therefore, using the procedure above, we can locate which orthogonal components may encode undesired knowledge. Then, we can remove the components from the pre-trained model and rectify the pre-trained model to give less undesired responses.
Result Highlights
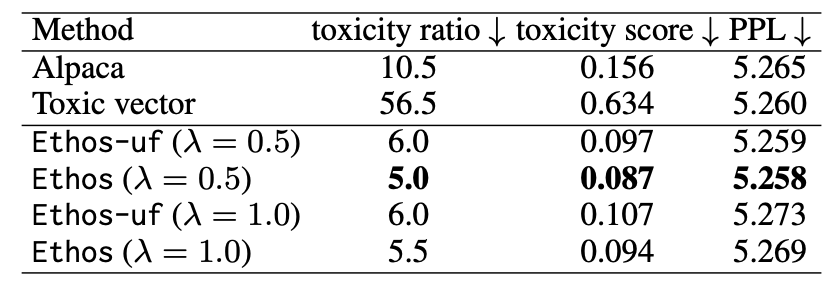
In the project, we evaluate the method on three scenarios: model debiasing, model detoxification, and model unmemorization. The table below lists the performance of model detoxification, which is aimed to reduce toxic responses from language models. We can see that the proposed method, Ethos, significantly reduce toxicity in reponses, while still preserving model utility (low PPL).
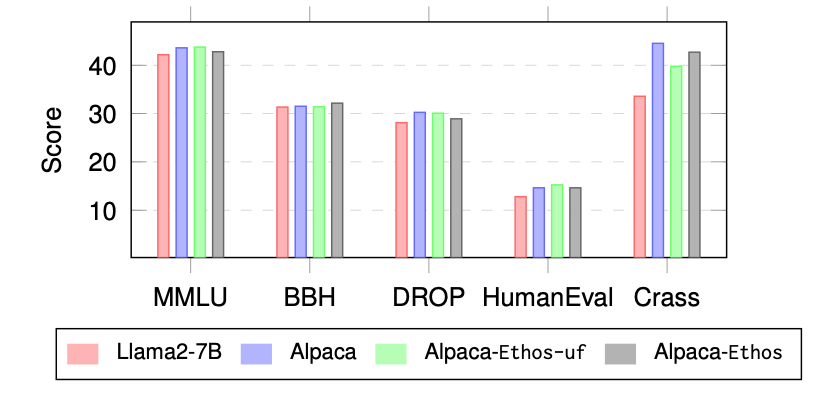
Furthermore, the figure below shows that the rectified model still performs well on common benchmark datasets, which indicates that we not only reduce toxic knowledge in the pre-trained model, but also preserve the model’s capabilities in general tasks.
Please check out paper for more details and results on other tasks such as model debiasing and model unmemorization.
Citation
@misc{NAACL24Ethos,
title={Ethos: Rectifying Language Models in Orthogonal Parameter Space},
author={Lei Gao, Yue Niu, Tingting Tang, Salman Avestimehr, Murali Annavaram},
year={2024},
eprint={2403.08994},
archivePrefix={arXiv},
primaryClass={cs.CL}
}